Prompts to Table: Structured Data Extraction with Promptflow
Welcome to the Prompts to table code repo! This contains some code to get started using this workflow for information extraction from medical texts. Check out the pre-print here.
What is this?
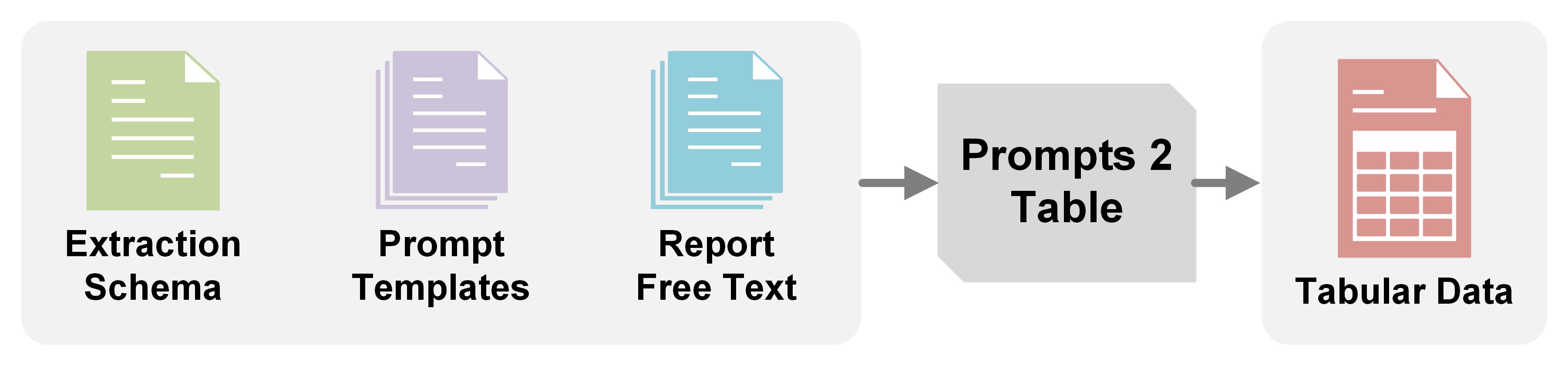
This repository contains code to extract structured data from unstructured text using a prompt-based approach. The goal is to convert free-text medical information into a structured format that can be easily analyzed and processed.
As mentioned in the pre-print, this specific workflow is not intended to be the “primary product”, we instead point readers to our tables (in both the main text and supplement) that introduce higher level considerations for using LLMs for clinical information extraction.
This quarto docs site has a lot of pages that are empty, right now I only have the main page and the quickstart page done. I may stop here if there isn’t much interest in using this code. However, if you are interested and want me to add more content, please feel free to open an issue or shoot me an email. david.hein@utsouthwestern.edu There is also an example Jupyter notebook in the main directory
How does it work?
The overall workflow is as follows:
- Define Your Target: You create an extraction schema specifying what information you want to extract (e.g., item names, expected labels/values) and entity specific instructions to guide the LLM.
- Run the Pipeline: Using the core
pf_batch_run_wrapperfunction, you point the toolkit to your input data (CSV or JSONL files containing report text) and your schema. - Automated Processing: The toolkit leverages Microsoft Promptflow to:
- Manage connections to LLMs (Azure OpenAI or standard OpenAI-compatible APIs).
- Orchestrate the extraction workflow based on your schema (supporting different patterns like report-level vs. specimen-level features or panels).
- Process reports efficiently in batches with configurable parallelism.
- Handle intermediate data preparation and cleanup.
- Structured Output: The final, complex JSON output from Promptflow can be easily converted into a flat, analysis-ready pandas DataFrame using the
flatten_outputsutility function.
Key Concepts
- Schemas: The heart of the process. Define your desired output structure, labels, and entity specific LLM guidance. (See the Schema Guide)
- Promptflow Engine: Provides the robust backend for workflow execution, logging, and scalability.
- Flexible Flows: Tailor extraction to different data scopes (report/specimen) and types (feature/panel). *(Learn more in Flow Types
- Simplified Interface: Primarily interact via the main wrapper function. (See the Quickstart or API Reference)
- Helper Utilities: Tools for data prep, result flattening, and even attempting to fix malformed JSON. (Explore the API Reference)
Getting Started
This project utilizes uv for managing the environment and dependencies. To get started, see the Quickstart guide. This will walk you through setting up your environment, installing dependencies, and running the first example.
The main orchestration code is located in app/helper_functions and can be imported into notebooks or scripts. The main function to run the pipeline is pf_batch_run_wrapper, which takes care of most of the heavy lifting.
Prompt flows
The app directory contains three subdirectories, each representing a specific type of data extraction flow. See the Flow Types guide for more details on how to use these flows.
Supported Models
Currently supported are OpenAI models through Azure, and OpenAI-compatible APIs. Instructions for adding connections is found in guides here.